I am excited to share with you today that starting Monday I will be joining the Big Data team at Intel. Yes, Intel. While not traditionally known for its software offerings, Intel has recently entered the Big Data space by introducing their own, 100% open source Hadoop distribution with unique security and monitoring features.
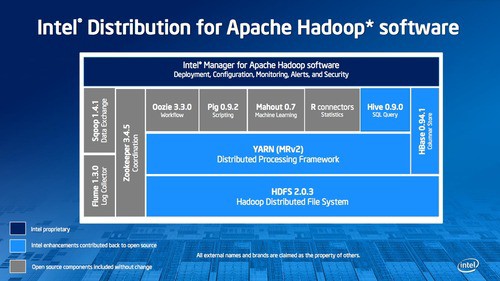
As illustrated by their Github repository, Intel has already done a lot of work with Apache Hadoop. The particular repos worth mentioning are their work on HBase’s security in Project Rhino as well as their work on advanced SQL support in Hive and performance enhancements for HBase in Project Panthera. In addition to these projects, Intel has also established Benchmarking Suite and Performance Analyzer projects which aim to standardize measurements around real-life Hadoop workloads.
As a solution architect, I will work on a team dedicated to designing the next-generation data analytics platform by leveraging the full breadth of Intel’s infrastructure experience with compute (Xeon processor), storage (Intel SSD), and networking (Intel 10GbE), as well as its cryptographic and compression technologies (AES-NI, SSE).
Why Intel
If you have read my blog over the last couple of years, you will know how passionate I am about data. I believe Apache Hadoop specifically represents a very unique opportunity for the enterprise as it challenges many preconceived notions about analytics, both from the scale as well as cost perspective.
My vision for Hadoop is for it to become a truly viable data platform: open, easy and performant.
A platform upon which the community can innovate and solve real complex problems. I joined Intel because it provides me the means to execute on this very vision. After all, Intel’s Hadoop distribution is the only open source platform backed by a Fortune 100 company.