Data is growing at an exponential pace. Based on recent numbers from IDC, the total amount of data in 2015 (4.4ZB) will grow to 44ZB in 2020. Franky, how much is in Zettabyte is almost inconsequential. It is the fact that all of the data generated since the beginning of time (at least the electronic part), will grow 10x in just the next four years that’s shocking!
{kind=link}
Since data is the new: “oil”, “gold” or even “bacon” it is natural to think we should value it as a yet another commodity: $0.20/GB. That perspective, I would argue, will lead us to miss even larger opportunity.
Device, role of the machine
The interesting part of these predictions is the fact that the majority of new data (90%) will be machine-generated; driven by the explosion of newly connected devices.
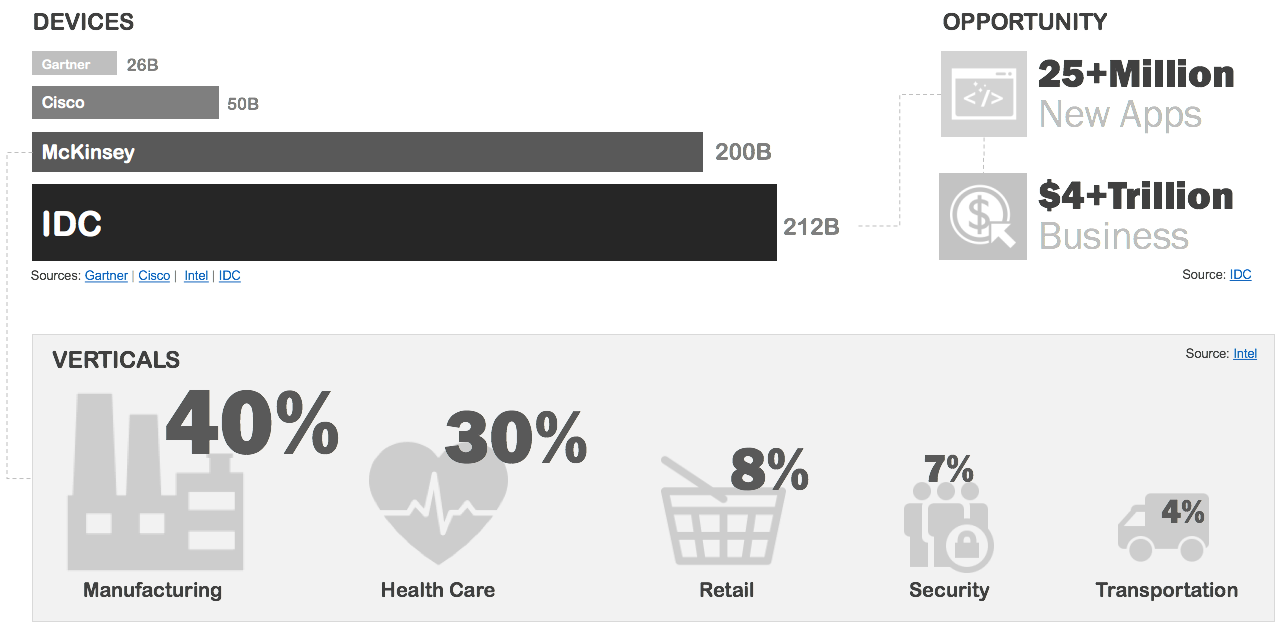
By all accounts we currently use less than a quarter of our data (22%) for anything meaningful! Perhaps the most surprising part of the IDC report is that while the data volume will grow 10x by 2020, our ability to derive insight from the newly generated data will increase only slightly (35%).
New device, new Data
Perhaps one of the reasons why our ability to extract value will not increase anywhere near the predicted growth of the volume is that much of the new data is fundamentally different from what you would find in a traditional warehouse or even a NoSQL application DB.
In a tractional systems we had star schemas with facts, each referencing number of dimensions. In NoSQL stores we went with duplicating data into each document. But, in both of these cases the data was managed with its context. Consider this example of an IOT sensor observation:

To a large degree, the machine generated data “observed” on the edge has no context. We have the time and a source of the observation (when) and reference codes for this observation’s place (where), as well as its subject (the what). In some cases there may even have additional attributes. To large degree, though, this is the only context we have at the point of collection.
To put it in practical terms, the light sensor on the corner of my street doesn’t know anything about the surrounding lights nor does it know its own location, only the codes which were embedded during the deployment. Yes, it has an ID which it sends with each observation. That ID does allow those who consume that data to derive some context about that observation by reconciling it to a larger project and referenced location. Still, by itself, the value of that individual event is nominal.
New device data value chain
That got me to think. If the volume of data will grow 10x over the next five years we ought to really figure out how to derive more of its value.
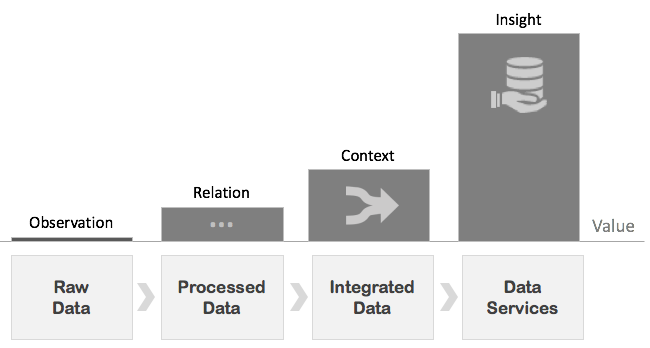
Inspired by thoughts on the subject from the likes of Dave McCrory and the SVDS team, I asked myself a question: what impacts the value of data and what is its value chain?
The first and more obvious part of the answer is that the value of a data series increases the longer it is observed. The second part, that’s perhaps less obvious, is that in many cases, the raw data will have nominal value until it is augmented with context. That made me realize that a single raw data set, in different context, can drive multiple insights; even more than just one value chain.
TLTR;
To a large degree, new device data has no value until it is integrated, and will not truly have its full potential realized until it is delivered as a service that answers specific business questions.
Yes, these ZBs of device data will lead to new revenue streams, but, that opportunity will not be measured in $/GB. The ones who stand to gain most from this opportunity are those who can answer questions faster and more accurately. More accurate models and faster services will improve performance and reduce operation costs. ZBs of raw data, not so much.