As part of my recent solution review, I wanted to compare a few performance metrics specific to multi-node data service deployment on different clouds. This post is about my experience with Google Compute Engine (GCE) as part of that evaluation.
API & Tools
When targeting developers, API and surrounding tooling is an absolute must. The ability to easily manage and automate cloud resources is something that developers demand. Their usage patterns require efficiency, which at that level, comes mainly from automation.
Here are three specific areas that set GCE apart from others. Remember, it is not that other providers do not have these (which in many cases they do not) but rather about how clean, explicit and simple GCE implementation is in these areas.
REST Interface
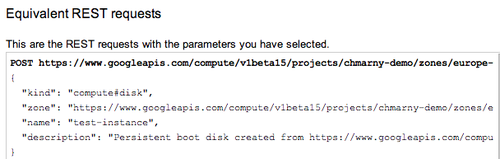
One of the benefits of REST as a cloud management interface is its consistent approach to provisioning and management of resources. To manage GCE, clients send authenticated requests to perform a particular action: provision network, create instances, associate disks, etc.
One of the nice GCE touches in assisting programmatic implementation is that the GUI interface to Cloud Console exposes REST and command line equivalent for each operation. This allows developers to simply copy the defined operation and use it in their automation tools to remove guesswork from the initial message format creation.
Command-line tool
gcutil is a command-line tool designed to help with management of GCE resources. Written in Python, gcutil runs natively on any UNIX-based OS or under Cygwin on Windows. The important thing to realize here is that while gcutil is a command-line tool; it still uses the same REST interface to message its commands to GCE.
One of the things that I often long for in cloud management APIs is support for multiple personas. With gcutil it is as simple as providing an existent credential file (--credentials_file). This way separating accounts is just a runtime flag away.
What makes gcutil really user-friendly for developers however is its ability to set default values for common operations. By caching values of common commands (--cache_flag_values), gcutil can reuse arguments like --zone or --machine_type across multiple commands.
Perhaps the part that makes gcutil most unique though is its ability to perform each command in either synchronous or asynchronous mode. By default, gcutil waits for each command to complete before moving returning control. In asynchronous mode, however, gcutil returns request id immediately after posting the request. This was a massive feature for me when testing number of cluster node discovery strategies.
These features combined with the ability to customize result format per each command: JSON, CSV, Table as well as the ability to return only the name of the newly created resources which allows for piping results from one command as on input to another, make gcutil one of the best though-through IaaS clients I’d ever seen.
Speed & Flexibility
In my short experience, I found instances and disk (yes, not “volumes”) provisioning as well as general instance startup on GCE to be fast. My specific interest was the time that it took to spin, configuring and terminating entire clusters of data nodes. In that specific use-case, CGE was faster than EC2, Azure or Rackspace.
The project metaphor, while somewhat awkward for me initially, quickly became for me a clear separation for distinct areas of work. Additionally, its integration with the advanced routing features allowed me to easily create gateway servers (aka VPN) to span clusters across local and GCE network.
For me personally, perhaps the biggest feature was the metadata support. In addition to the basic key value pair tags, every GCE instance also supports metadata. In addition to including information defined by the service itself like instance host name, it can also include user-defined data.
gcutil addinstance node-${NODE_COUNT}" \
--metadata="cluster:${CLUSTER_NAME}" \
--metadata="index:${NODE_COUNT}" ...
Update:
gcutilis now deprecated in favour ofgcloud compute. More info on transitioning here.
Instance configuration, as well as the configuration of other instances in the same project, is available in a form of a REST query against the provisioned metadata server. This metadata can also include project-level metadata.
The place where this capability really came handy for me was node-level metadata. By simply defining metadata value for a node index, I was able to have individual data nodes define their own unique cluster names (–metadata=name:node-0) as well as query the project-level data for cluster name.
Custom metadata becomes especially useful when using startup scripts to execute during instance boot. Using gcutil, I was able to pass in a single local startup scripts using the –metadata_from_file flag and have it discover its variables from metadata parameters.
NODE_INDEX=$(curl http://metadata/computeMetadata/v1beta1/instance/attributes/index)
Pricing
In my particular test cycles, I must have deployed close to 1000 individual instances across EC2 and GCE. Each one of these instances stayed up for maximum 15–20 minutes, just enough to run a set of tests on the new cluster. The part that makes GCE a lot more compelling for these kinds of use-cases is the granular pricing. Google prices its instances in one-minute increments with 10-minute minimum; not hourly, like EC2.
One area where GCE is perhaps not as flexible as I would like is in the area of billing. I do like the flexibility to charge individual projects to different credit cards, but would like to see a consolidated billing option there too. Also, this is the one area that is not supported by the API!
GCE seems like a fundamentally different type of IaaS, designed specifically with developers in mind. While probably not much of a challenge to EC2 anytime soon, over time though, provided they augment their service offering list, GCE’s focus on developers will pay off. Having experienced their tools first hand, it is clear these guys know how to run infrastructure at a massive scale without alienating developers.