The “high-priests” of Big Data have spoken. Hadoop Distributed File System (HDFS) is now the de facto standard platform for data storage. You may have heard this “heresy” uttered before. But, for me, it wasn’t until the recent Strata conference that I began to really understand how prevalent this opinion actually is.

Perhaps even more important, how big of an impact this approach to data storage is beginning to have on the architecture of our systems.
Since the Strata conference, I’ve tried to reconcile this new role of HDFS with yet another major shift in system architecture: the increasing distinction between where data sleeps (as in where it is stored) and where data lives (as in where it is being used). Let me explain how one relates to the other, and why I actually now believe that HDFS is becoming the new, de facto standard for storing data.
HDFS Overview
HDFS is a fault-tolerant, distributed file system written entirely in Java. The core benefit of HDFS is in its ability to store large files across multiple machines; in distributed computing commonly referred to as “nodes”.
Because HDFS is designed for deployment on low-cost commodity hardware, it depends on software-based data partitioning to achieve its reliability. Traditional file systems would require the use of RAID to accomplish this same level of data durability, but, in HDFS’s case, it is done without dependency on the underlining hardware. HDFS divides large files into smaller individual blocks and distributes these blocks across multiple nodes.
It is important to note that HDFS is not a general-purpose file system. It does not provide fast individual record lookups, and, its file access speeds are pretty slow. However, despite these shortcomings, the appeal of HDFS as a free, reliable, centralized data repository capable of expanding with organizational needs is growing.
Benefitting from the growing popularity of Hadoop, where HDFS is used as the underlining data storage, HDFS is increasingly viewed as the answer to the prevalent need for data collocation. Many feel that centralized data enables organizations to derive the maximum value from individual data sets. Because of these characteristics, organizations are increasingly willing to ignore the performance shortcoming of HDFS as a “database” and use it purely as a data repository.
Before you discredit this approach, please consider the ongoing changes that are taking place in on-line application architectures. Specifically the shift away from direct queries to the database and increasing reliance on law latency and high-speed data grids that are distributed, highly optimized, and most likely host the data in memory.
Shift in Data Access Patterns
Increasingly, the place where data is stored (database) is not the place where the application data is managed. The illustration that perhaps most accurately reflects this shift is comparing data storage to the place where data sleeps and data application to the place where data lives.
Building on this analogy, the place where data is stored does not need to be fast; it does however need to be reliable (fault-tolerant) and scalable (if I need more storage I just add more nodes).
This shift away from monolithic data stores is already visible in many of today’s Cloud-scale application architectures. Putting aside the IO limitations and the obsessive focus on atomicity, consistency, isolation, durability (ACID) of traditional databases, which leads to resource contention and subsequent locks. Simply maintaining speed of query execution as the data grows in these type of databases is physically impossible.
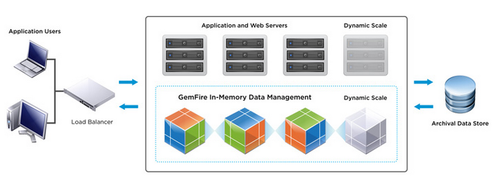
By contrast, new applications architected against in-memory data grids benefit from already “buffered” data, execute queries in parallel, and are able to asynchronously persist modifications to storage, so that these operations do not negatively impact their performance. This approach results in greater scalability of the overall application and delivers raw speed in order of magnitude compared to disk-based, traditional databases.
It is important to realize that these in-memory data grids are not dependent on the persistence mechanism and can leverage traditional databases as well as next-generation data storage platforms like HDFS.
New Data Storage Architecture
As in-memory data grids become the backbone of next-generation on-line applications, their dependency on any specific data storage technology becomes less relevant. Overall, organizations want durable, scalable and low-cost data storage, and HDFS is increasingly becoming their consolidated data storage platform of choice.
As you can imagine, this is not an all-or-nothing situation. Whatever the specific workload is — write-intensive or demanding low-latency — HDFS can support these requirements with a variety of solutions. For example, an in-memory grid can be used for sub-second analytical processes of terabytes of data while persisting data to HDFS as a traditional data warehouse for back-office analytics.
Considering the relatively short life span of HDFS, its ecosystem often displays maturity. Solutions like Cloudera’s open source Impala can now run on the raw HDFS storage and expose it to on-line workloads through a familiar SQL interface without the overhead of MapReduce (as it is implemented by Hive).
The Kiji Project is another example of an open source framework building on top of HDFS to enable real-time data storage and service layer for applications. Impala and Kiji are just a few frameworks of what is likely to become a vibrant ecosystem.
Many organizations have already started to leverage HDFS’s capabilities for various, non Hadoop-related applications. At Strata, I attended a session HDFS Integration presented by Todd Lipcon from Cloudera and Sanjay Radia from Hortonworks. It was a great overview of the vibrant technological integrations of HDFS with tools like Sqoop, Flume, FUSE or WebHDFS…just to name a few.
HDFS has also a large set of native integration libraries in Java, C++, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk and many more. Additionally, HDFS has a powerful command-line and Web interface as well as Apache HBase project, which when necessary, can run on top of HDFS and enable fast record-level access for large data sets.

Once the data is centrally located, there is a well-documented concept of Data Gravity originally created by Dave McCrory, which among many other things has the effect of attracting new applications and potentially resulting in further increase of the data quality and overall value to an organization.
I am not saying that all future data processing frameworks should be limited to HDFS. But, considering its prevalence in the Big Data market, low-cost, and scalability, and when combined with the vibrant ecosystem of libraries and project, it may be wise for organizations to start consider HDFS as their future-proof data storage platform.