The presentation that goes along with this post is available here
In my last post I went over the value cycle of machine generated data. In this post, I want to follow up with a few ideas on how to further amplify value of that data by expanding its context beyond the walls of owning organization, in a construct we came to know as Data Exchange, and list a few innovation opportunities in each one of these areas.
Before we start though, it is worth mentioning that there are many reasons why exchanging data with external partners is not always possible (privacy, intellectual property, legal constraints around ownership etc.). In my experience, however, these challenges represent but a small subset of the overall data market and even in most stringent environments can be overcome through anonymization, de-identification or distributed access patterns where the data in question never actually leaves the walls of the owning organization.
Lower OPEX
Let’s start with the basics: minimizing the cost associated with sharing data. Nobody is going to share data if the cost of its exchange is higher than its perceived market value. I’m stressing the “perceived” here as in some cases the monetary value of data may be small, but its value to the society at large may outway any costs associated with its sharing (i.e. health or environmental search). As with many service economies, the largest part of cost data exchanges is often the human labour. That’s why to assure these data exchanges are sustainable, they must be built from ground-up with a fanatical focus on automation.
Opportunities:
- Reusable data source connectors
- Appliance gateways with robust APIs for scheduling, validation, alerts
- Verifiable and trusted audit capabilities
Add Context
Raw data alone, especially when machine generated, is often not of high value. In most cases, however, you can easily and significantly improve its value by creating new views by relating connected data sets. This approach allows for same data sets to be used in multiple views to expose otherwise not obvious insights. By adding context, data exchanges have also the opportunity to become a birthplace of organic sets. Subsequently that new organic set itself becomes a component of a new view which further amplifies the value…and so on.
Opportunities:
- Generic link-mining utilities building associative structures
- Distributed data curation services with lineage preserving capabilities
- Dynamic record “decoration” for on-read data stream
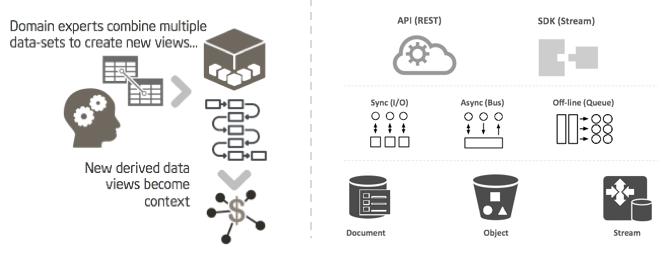
Deliver Diverse APIs
In most cases, exchanging raw data is not a very helpful or sustainable model. Instead, create an abstraction layer for domain specific services. This kind of highly-optimized service will significantly amplify value of the raw data and increase the monetization opportunities associated with that set. For example, instead use a simple per GB charge model, this approach would allow more granular query access plans with protocol-specific charge plans (i.e. REST vs. DDS-based API). This also allows for more granular data queries based on the input parameters, which would certainly increase the stickability of such service.
Opportunities:
- API management, bindings
- Federated and granular ACLs
- Deep metering, telemetry capabilities
Create Data Bazar
Data exchanges, whether simple bit-shipping platforms like Data.gov or more granular data delivery services like Nielsen, suffer form the the same problem: their relevance decreases after the initial use. To avoid this, exchanges should aim to create a data bazar. By that, I mean a set of services beyond simple data delivery. Instead, a bi-directional exchange with value consumption at multiple levels: not only data providers and consumer but also data scientists, curators and domain-specific analysts.
Opportunities:
- Model and service gamification
- On-demand data scientists, and domain analysts
- In-platform competitions and hackathons
As the data market continues to mature and our ability to derive value from machine generated data increases, more exchanges will be created. The part that excites me though, is that with the growing number of infinite data streams data exchanges will have to enable distributed data queries (avoid duplication) and support adaptive model training use-cases (dynamic rules)…but that’s a subject for another post.