
Today marks a bittersweet moment as I say goodbye to Cruise. When I joined the company seven months ago, my mission was to scale the AV services worldwide and to modernize the AV and Cloud service developer platforms. Despite the unexpected challenges following the October incident, my journey at Cruise has been incredibly enriching, teaching me the true essence of resilience, adaptability, and commitment to excellence.

The practice of Secure Software Supply Chain (S3C) can get complex at times. Fortunately though, a large portion of the key things we can do to secure our software delivery pipelines are actually pretty easy. This post covers three concepts you can implement today:

If you are doing any vulnerability detection in your software release pipeline today, you are already familiar with the volumes of data these scanners can generate. That dataset gets significantly larger when you add things like license scanning and Software Bill of Materials (SBOM) generation. That volume of data gets further compounded with each highly-automated pipeline you operate. This can quickly lead to what I refer to as a Software Supply Chain Security (S3C) data fatigue, as many vulnerabilities you’ll discover you simply can’t do anything about. There is an actionable signal in there actually, it’s just hard to find it in the midst of all the noise.

 Twitter does provide notifications for when new users start following you. It does now however provide any notifications when users stop following you. Now, there is an ample of web sites out there who do provide that service, in most cases though, they cost money, and ask you for a complete access to your Twitter account.
Twitter does provide notifications for when new users start following you. It does now however provide any notifications when users stop following you. Now, there is an ample of web sites out there who do provide that service, in most cases though, they cost money, and ask you for a complete access to your Twitter account.
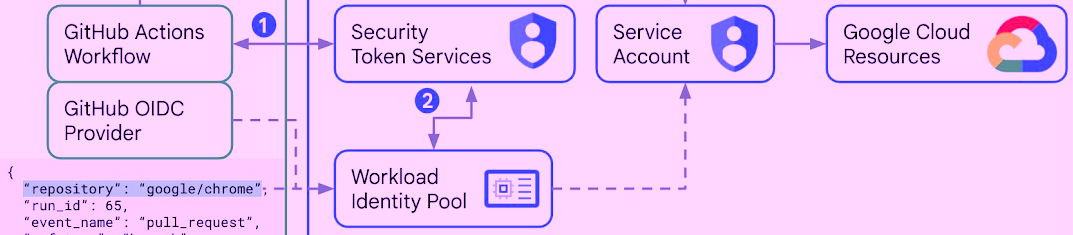
The recently introduced by GitHub support for OpenID Connect (OIDC) tokens in GitHub Actions allows workflows to mint new tokens and then exchange those tokens for short-lived OAuth 2.0 or JWT tokens. These tokens can be used to access and manage Cloud resources. This is all done without the need to store the traditional long-lived service account keys in a form of GitHub secrets.

I learn best by doing. And recently, most of the projects I’ve been building are either REST or gRPC-base services deployed as container images into Cloud Run on GCP. That means that I increasingly find myself recreating a lot of the same infra and app deployment flows.

Why not Medium
My main reason for migrating off Medium was the paywall Medium introduced while back. I actually understand why they did it. The unlimited access price: $5/month ($50/year) is too high, but still, I get it.
For me though, the objective was to allow readers to easily discover and read my posts. I don’t want my readers to experience any friction. Forcing the reader to deal with the frustrating Medium up-sell pop-ups just to read my post was just unnecessary.

Increasing large amount of technical news I read come from the posts shared on Hacker News or on Twitter. While both of these services have search options, neither of these seem to be advanced enough to narrow my searches at the desired level or to setup automatic delivery.

All complexity needs to be abstracted, right? This reductionist statements misses nuance around the inherent cost/benefit tradeoffs, especially when you consider these over time.
Don’t get me wrong, there often are good reasons for additional layers to make things simpler (grow adoption, lowering toil, removing friction, etc.). Still, these layers come at the long-term cost that’s often is not a part of the evaluation process.

I recently joined the Office of CTO in Azure at Microsoft and wanted to ramp up on one of the open source projects the team has built there called Dapr. Dapr describes itself as:
A portable, event-driven runtime that makes it easy for developers to build resilient, microservice stateless and stateful applications that run on the cloud and edge and embraces the diversity of languages and developer frameworks.